Distributed Systems with Nodejs: My notes and review

I have recently finished reading the book Distributed Systems with Nodejs Building: Building Enterprise-Ready Backend Services by Thomas Hunter II.
This post is to share the notes I’ve taken. I took my notes without a public audience in mind. If you find any mistake you want to correct, please leave a comment or reach out via LinkedIn.
The notes will be organized by chapter. At the end of the post, I will write a short review of what I have learned and found interesting.
Why distributed ?
This chapter is an overview of JavScript (its single-threaded nature) and Nodejs (the internal architecture).
JS is single-threaded we can use “Cluster module” or “Worker thread” to run multiple workers but they can’t share data between them to do that we can use “message passing” or “shared Araay buffer”.
Concurrency in JS refers to the ability of the NodeJS Event loop to run and schedule tasks for execution in the call stack.
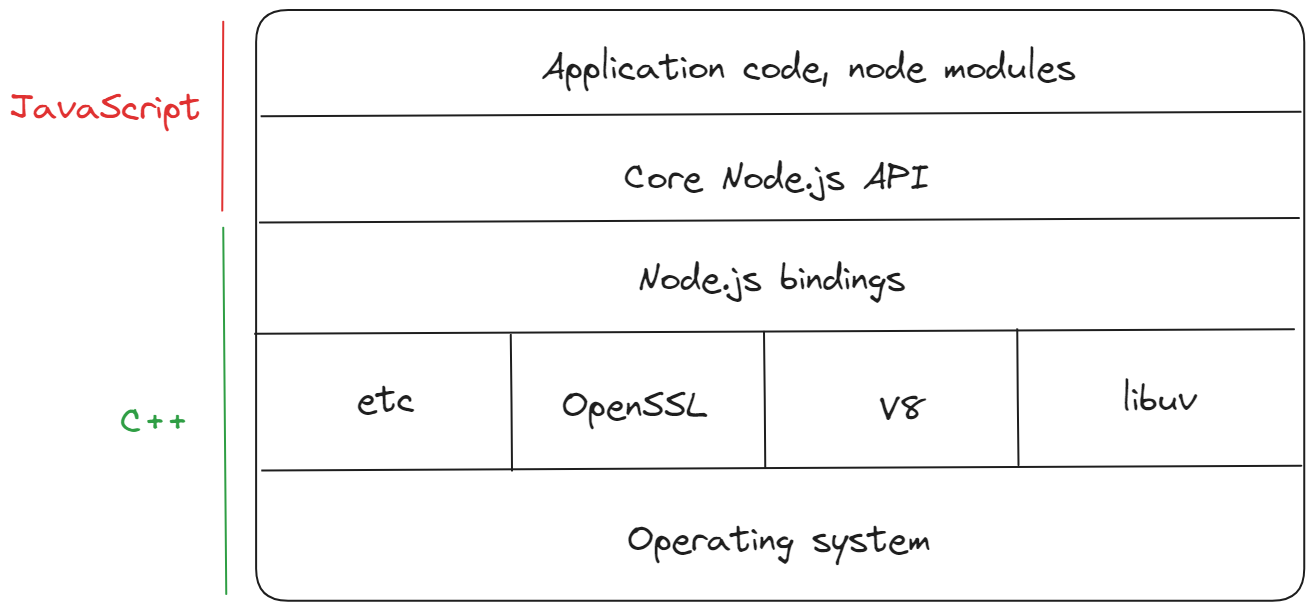
Libuv maintains a pool of threads to handle I/O and CPU-heavy tasks. the default size is 1024 but we can override it by editing UV_THREADPOOL_SIZE.
In NodeJS setTimeOut returns an object rather than a number like in the web browser.
The Event loop in NodeJS has multiple phases:

Running too many stacks will stall the event loop. Don’t use the process.nextTick() to offload tasks.
Protocol
A protocol is a standardized format for communicating between two parties.
TCP is a stateful protocol responsible for establishing communication between two devices or networks.
HTTP is an application layer protocol used to transfer HTML and other media over the internet (web browsers and web servers). It’s used on top of TCP.
It’s possible to compress HTTP’s body to reduce the data sent over the network and inform the server or client which algorithm has been used. We can use the ACCECPT-ENCODING to inform the server that we accept compression and once the server has chosen which algo it will inform the client by using the CONTENT-ENCODING.
The HTTP compression works only for the request body but HTTP/2 uses HPACK to compress header.
HTTPS/TLS: TLS is the protocol used for encrypting HTTP traffic. It generates two keys one public and one private.
GraphQL: it’s a query language that defines a contract through which a client communicates with an API server. GraphQL schema are string that describes all the interactions a particular GraphQL server can make. It describes objects and types as well.
// schema
Types describe the data you can either fetch or write via the GraphQL endpoint.
Resolvers are the logic to resolve a request from the user.
GraphQL exposes only one endpoint /graphql which is used to make Queries (fetching data) and mutations (editing, posting, or deleting data).
gRPC: gRPC (gRPC Remote Procedure Call) is a modern RPC framework developed by Google. It builds on the traditional RPC concept but incorporates several modern features and enhancements.
It allows a client to invoke a method located on a remote machine. Unlike REST and GraphQL it doesn’t share data in plainText but uses Protocol buffer.
Scaling
Running multiple instances of the same service can help handle the traffic. We can cluster module or a reverse proxy.
Cluster module: it runs multiple instances of the service on the same machine. They will all share the same PORT.

const cluster = require('node:cluster');
// setup the master node
const cluste.setupMaster({exec: ''}
// create workers
cluster.fork();
cluster.fork();The disadvantages of this approach are CPU and Memory usage since everything is on the same machine.
Reverse proxy: it’s a tool that receives a request from the client and forwards it to the appropriate server.
The advantages:
- Validate HTTP request
- perform encryption
- forward request to a healthy server
- hide your service addresses
- distribute service to multiple machines.
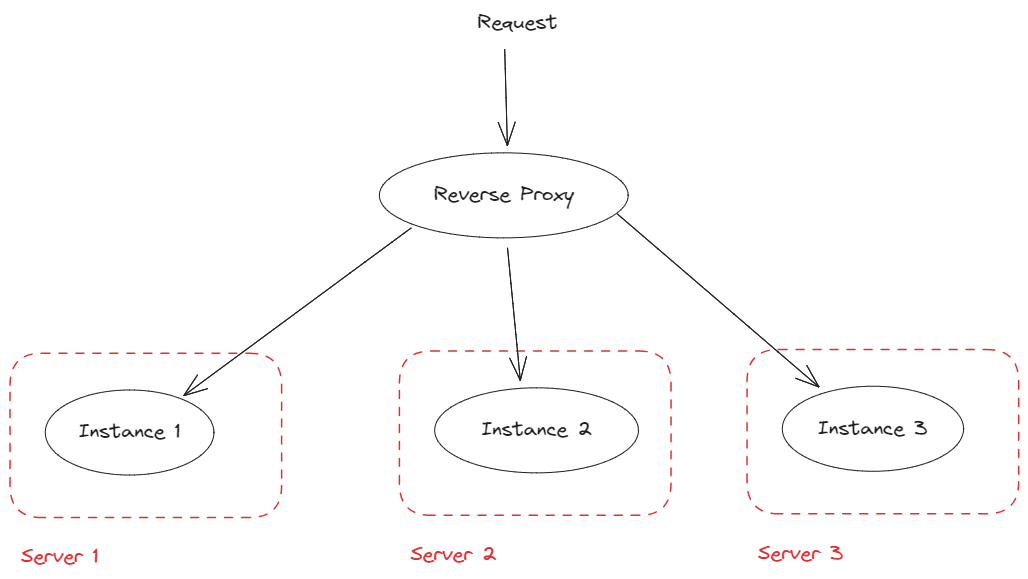
Here the author uses HAproxy which has Round robin as the default algorithm to balance the charge between the instances. The reverse proxy will distribute the traffic evenly to each server, request 1 to server A, request 2 to server B, and so on.
Since we can have endpoints that take some time to handle an incoming request the dev can set the MAXIMUN_CONNECTIONS of our server to a given number but that means if the server receives more than that number of concurrent requests they will be dropped. To solve that issue we can use the reverse proxy to create a kind of queue and forward a request to a given server only if it can handle it.
SLA and load testing: SLA stands for Service Level Agreement. It is a contractual agreement between a service provider and a customer that outlines the level of service expected from the provider. Engineers can calculate the number of requests their service can handle by using a load-testing tool like autocannon.
autocannon -d 60 -c 10 -l http://localhost/api/users- -d: specifies the duration of the test in seconds
- -c: specifies the number of connections to use during the test
- -l: enables the latency output mode. This mode provides additional latency metrics such as minimum, maximum, and average latency for each request.
For the Req/Sec we should rely on the “1.X” column.
SLO: it’s a set of measurable metrics engineers set for their services about their availability, latency, and so on so they can meet the SLA. While defining SLO if the service relies on a third-party API the response time should be included in the SLO.
Observability
Observing a service that runs on a faraway land is more complicated than the one running locally we need a different set of tools more sophisticated than our debugger or console log.
We should always have multiple environments. Environment is a concept of differentiating running instances of an application. They should always be isolated from each other by running on different physical machines or VPC. The recommended environments are prod, staging, and dev.
To gain a better understanding of a system running in production we mostly rely on three pieces logs, metrics, and distributed tracing.
Logging with ELK: Log severity or Levels:
- Error
- Warn
- Info
- Verbose
- Debug
- Silly
Setting a level threshold in production is common since logs can be resource-consuming. If the threshold is set to “Verbose”, the logs of levels “Debug” and “Silly” will be dropped.

Logstash can ingest log via UDP. To configure logstash to listen for UDP messages a configuration file should be created and mounted then it will be available for the docker container.
Once everything is set up and logs are ingested we can create a dashboard or directly type a query for debugging using KQL.
Metrics with Graphite, StatsD, and Grafana: Usually we want to know about data aggregation as values grow and shrink over time.

A metric is numeric data associated with time, request rate, number of 2xx, and 5xx errors (HTTP), latency, memory, CPU usage, and even business info.
Distributed Tracing with Zipkin: it’s a way to trace an incoming request through your system when you have a complex one (multiple services talking to each other).
Tracing tools will attach the following information to every request.
- traceId: a unique identifier to the request. it is generated when the request enters your system.
- spanId: a request within the service.
- parent.spanId: the service that has sent the request.
- sampled: if a request should be reported or not.
hile using the Zipkin-lite package, we must manually instrument the app by calling hooks.
onRequest() is called when a request starts and injects objects that can be used throughout the request lifecycle then at the end the onResponse() is called which calculates the overall time of the request.
Healthcheck: here the author talks about adding a healthcheck endpoint that will return a status according to the tools or external service connected to our app such as cache or database.
ioredis provides a reconnection system that PG doesn’t offer.
Alerting with Cabot: in this section, the author explains the importance of alerting engineers when a piece of infrastructure goes wrong. We use Cabot, a lightweight and self-hosted alerting system that performs HTTP requests to the healthcheck endpoint and sends alerts to people on the call. It can also send alerts based on data in Graphite.
Containers
The ideal situation is that a program can be very quickly deployed regardless of whatever dependencies it has and the underlying OS should also be easily removed when not needed. That’s where containers come into play.
A Docker container is the instance of the image running with configuration such as name port mapping, volume mapping, etc.
Alpine is an extremely stripped-down Linux distribution and is often the base image of choice.
Docker-compose: it allows the configuration of multiple dependent dockers using a declarative docker-compose.yaml file. The file contains the same configuration data that can be represented as docker run flags.
Deployments
A deployment in the simplest sense is the movement of code from one location to another. In practice, a deployment is a much more formal process than “just copying come file”. The deployment process is usually made up of many stages. Other things need to happen as well, such as checking out the source from version control, installing dependencies building/compiling, running automated tests, etc. The collection of stages required to deploy an application is referred to as a build pipeline.
Regardless of the tool used for managing a build pipeline, some concepts are almost universally used.
Build: a build is when a snapshot (such as a particular Git commit) of an application’s codebase is converted into an executable form.
Release: a release is a combination of a particular build with the configuration settings. For example, one build might be released for both staging and production environments where it will have two different configurations.
Artifact: it’s a file or directory produced at some point during the build pipeline.
Each new release should have its name. This name should be a value that increments such as an integer or a timestamp.
Container orchestration
A container orchestration tool manages the lifetimes of many ephemeral containers. Such a toll gas ma y unique responsibilities and must take into consideration situations like the following:
- Containers need to scale up and down as the load increases and decreases
- New containers are occasionally added as additional services are created
- A single machine may not handle all the containers required by an organization.
It works great with stateless services, like a typical Node.js service where instances can be destroyed or re-created without having many side effects.
Kubernetes is an open-source container orchestration tool created by Google.

- container: is an isolated environment that encapsulates and runs the app.
- Volume: provide a way to mount a file system into a container.
- Pod: it’s the smallest unit that Kube API allows to interact with. A pod can contain multiple containers.
- Node: it’s a worker machine physical or virtual. Each node should have a container daemon (Docker), Kubelet, and a Network Proxy (Kube proxy).
- Master: it’s a set of services that are run on a master node (etcd, API server, scheduler, controller, and cloud controller manager).
- Cluster: it’s the overall collection of the master with the worker nodes.
Some Kubernetes concepts:
- Scheduling: is the action of looking for the best node to insert a new pod.
- Namespace: it’s a way to logically create an isolated collection of services within the cluster.
- Labels: are key-value pairs that can be assigned to resources (deployment, pod, and so on).
- StatefulSets: it’s a set of features (persistent volume, IP address) for managing stateful services like databases and cache.
- ReplicaSets: it’s responsible for making sure that a desired number of replicas for a given pod is available by creating and deleting pods.
- Deployments: it’s a resource that defines the desired state for a service it contains the container image, number of replicas, and environment variable.
- Controllers: tell Kube to change from one state to another.
- Service: defines how to expose a pod within the cluster.
- Ingress: defines how to expose a pod outside of the cluster.
- Probe: check if a pod is healthy and ready to receive requests.
When creating a deployment it creates a replica set which will create pods. To interact with the pod we have to expose it by creating a service.
The relation or link between services and pods is done by selectors and labels.
Removing a deployment will remove the replica set and pods.
- how to enable ingress while using minikube
minikube addons enable ingress // it uses Nginx by default- How to scale replica number
kubectl scale deploy `deploy-name` --replicas=4When deploying a new version of an application the old version is left behind by setting the replica number to 0.
- How to see the deployment history
kubectl rollout history deployment.v1.apps/web-api--record=true tells Kube to track the command used to change the app version.
Resilience
Application resilience is the ability to survive situations that might otherwise lead to failure.
- When a call to an upstream service fails the service should retry not crash
- When the database connection is lost the service should reconnect not crash.
- When the cache connection is lost the app should still respond to the client request.
Process Exit: it’s used to terminate the NodeJS process 0 means that it’s okay and any other numbers mean that there is an issue. We should log the error before exiting.
Exceptions: it’s something that has been thrown.
Rejections: it’s what happens when a promise has failed.
Signals: they are a mechanism provided by the operating system to allow programs to receive “short messages” from the kernel or other programs. It’s usually number 1 for SIGHUP and 2 for SIGINT. 9 for SIGKILL they are all meant to terminate the program.
Error: it’s a global object available in JS. It has metadata such as name, message, and stack trace.
It’s important to keep the state outside of the application due to the ephemeral nature of containers, and the fact that you and I wrote buggy code lool. If the state isn’t kept outside it can be lost forever or lead to inconsistent data.
Having a single source of truth is a philosophy that there is a single location where any particular piece of data must be called home.
Database connection resilience: Node.js applications often maintain a long-lived connection to one or more databases so that they may remain stateless. They are usually made through a TCP network connection. When a connection drops your application might be dead in the water.
- Automatic reconnection: it’s a mechanism that will automatically try to reconnect to your database when the connection is lost
- Connection pooling: the application maintains multiple connections to the db once a connection is lost it attempts to create a new one to compensate. When there is a new request the app will choose which connection to use.
Schema migration in production: a migration is a change that is made to the database schema.
- Use the timestamp for the migrations file to avoid conflicts
- The database will use a db table to track the migrations that already have been run.
The advantage of migration is that they can be reverted if an error happens in production.
We should use multistage live migration when migration is complex and can cause data lost in production.
Idempotency and messaging resilience: considered having idempotency if the system can have issues due to duplication.
Distributed Primitives
Few things to note here just read the Redis documentation.
Security
Security is an important concern for all applications, especially for those exposed to the network. I have noted a few things here:
- use environment variable
- use secrets
- use tools like Dependabot for dependency vulnerability fixes.
- you can use commands like npm outdated to display the current version you are using and the latest one for each dependency.
Review
Honestly, I have enjoyed reading the book, if you are a junior or mid-level engineer who wants to learn how to build enterprise and production-ready applications you will gain some best practices. You will learn how not to block the nodejs process, build resilient applications, deploy, and observe them once in production. For each package used in the book the author always provides some alternatives.
But if you are a more experienced software engineer who already knows those things you won’t learn anything new, the chapter about distributed primitive is more of a deep dive into the method Redis provides; the security chapter only addresses nodejs packages security. I think this isn’t a “Distributed System” book since there are many things that aren’t mentioned here it’s more a book about building production-ready nodejs service as I mentioned above.
Nonetheless, I recommend the book for junior or mid-level engineers it’s a good starting point.